Services
Branchen
Unternehmen
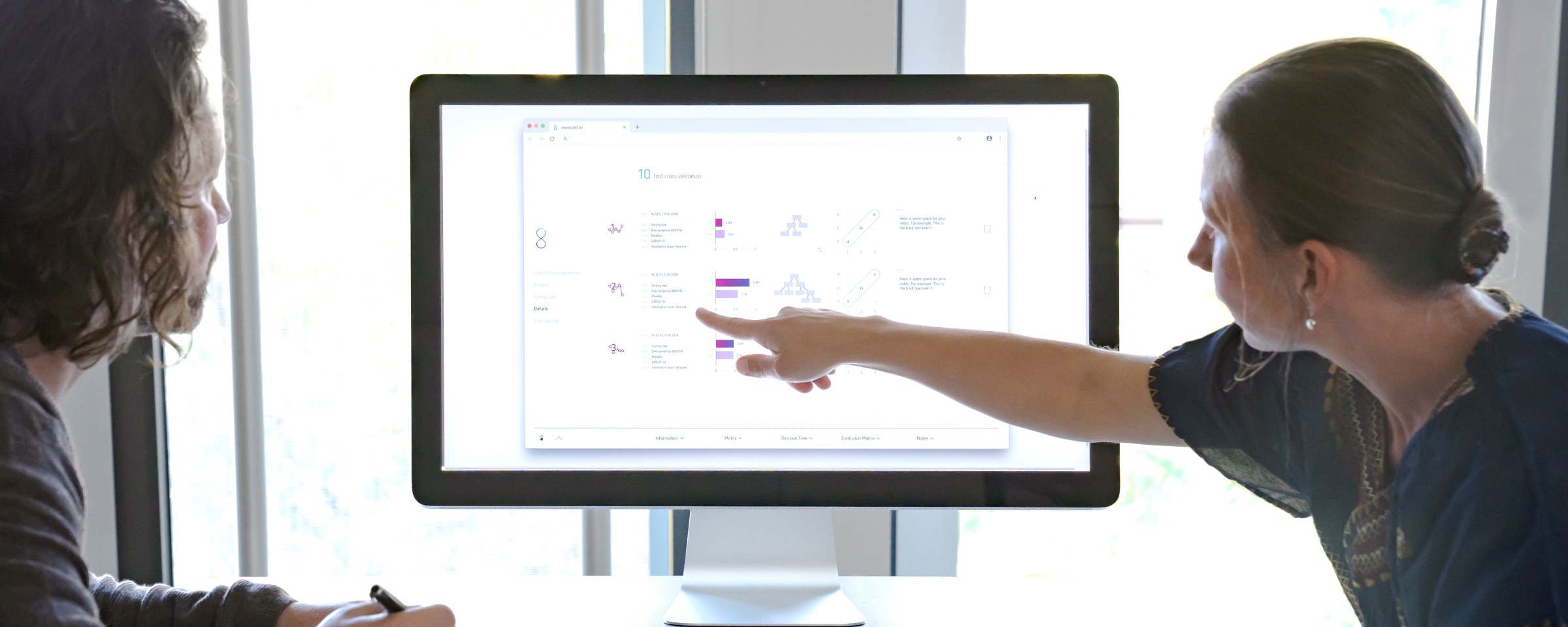
Intuity Machine Learning Assistant – KI-Modelltraining im Autopilot
Bei Intuity sind wir es gewohnt, in iterativen Prozessen zu arbeiten, bei denen Prototyping Ideen greifbar und erkundbar macht. Wir wollten denselben Prozess für Machine Learning nutzen.
Was ist Machine Learning?
Wenn wir in diesem Artikel über Machine Learning sprechen, meinen wir statistisches Machine Learning, und genauer gesagt überwachtes Lernen. In weniger technischen Begriffen: Angenommen, du stellst handgemachte Schokolade her und verkaufst sie. Da du nur einen kleinen Marktstand hast, kannst du nur drei deiner zehn Schokoladensorten ausstellen. Jede Woche musst du entscheiden, welche Schokolade du produzieren und zum Markt mitnehmen willst. Im Laufe der Jahre hast du Daten in einer Tabelle erfasst, zum Beispiel für jedes Datum und den Markttag die Anzahl der verkauften Schokoladenstücke jeder Sorte. Du möchtest die Anzahl der Schokoladenstücke pro Sorte, die du wahrscheinlich in der nächsten Woche auf dem Markt verkaufen wirst, mithilfe von maschinellem Lernen vorhersagen.
Im engsten Sinne des maschinellen Lernens — und dem, der die Forschung seit Jahrzehnten dominiert — würdest du deine Tabelle in ein maschinelles Lernwerkzeug einspeisen. Das Ergebnis ist eine Funktion, die die Anzahl der Schokoladenstücke vorhersagt, die du zu einer bestimmten Zeit und an einem bestimmten Ort verkaufen wirst.
Leider funktioniert das selten. Stell dir vor, dass eines Tages ein wohlhabender Liebhaber von Pekannüssen deinen Stand besuchte und alle deine Pekannussschokoladen kaufte. Dies ist ein seltenes Ereignis, das wahrscheinlich nicht wieder vorkommt. Die Zeile in deiner Tabelle, die die Daten dieses Tages enthält, könnte einen Lernalgorithmus irreführen, eine viel höhere Nachfrage nach Pekannussschokolade vorherzusagen, als ohne diese Zeile. Daher ist es oft ratsam, Daten vorzuverarbeiten, bevor sie in den Lernalgorithmus eingespeist werden. Neben dem Entfernen von Ausreißern kann eine solche Vorverarbeitung Daten-Skalierung, -Balancierung oder die Behandlung unbekannter Werte umfassen. Solche zusätzlichen Operationen an Daten werden jetzt von maschinellen Lern-Frameworks oder anderen Statistik-Tools unterstützt.
Die Datenvorverarbeitung bezieht sich auf die Zeilen deiner Tabelle, aber du musst auch die Spalten berücksichtigen. In unserem Beispiel haben wir möglicherweise das Datum des Markttags erfasst. Aber was können wir erwarten, aus den Daten vom 5. April 2015 vorherzusagen, wenn wir uns für unsere Planung für den 13. November 2018 interessieren? Interessanter wären Informationen wie der Wochentag oder die Jahreszeit, da diese allgemeiner sind und auf zukünftige Tage anwendbar sind. Wir könnten sogar neue Spalten in unsere Tabelle aufnehmen, die das Wetter dieses Tages oder irgendwelche Ereignisse in der Marktstadt enthalten. Während es einige automatische Unterstützung für die Auswahl von Merkmalen (also die Spalten, die wir verwenden wollen) aus vordefinierten gibt, ist für die Definition der Merkmale und die Hinzufügung von Daten Expertenwissen aus dem Fachgebiet unverzichtbar.
Noch allgemeiner könnten wir unsere ursprüngliche Frage überdenken. Wollen wir wirklich die Anzahl der verkauften Schokoladenstücke jeder Sorte vorhersagen? Könnten wir das Problem so umgestalten, dass es direkt die drei Sorten ausgibt, die wir nächste Woche zum Markt mitnehmen sollen? Oder gibt es möglicherweise andere Überlegungen, die wir nicht direkt in einen maschinellen Lernalgorithmus einfließen lassen können. Die Schokolade, die wir verkaufen, muss zuerst produziert werden. Unsere Entscheidung könnte also auch von der Verfügbarkeit und dem Preis frischer Zutaten abhängen. Wir könnten ein weiteres Lernproblem hinzufügen, das solche geschäftlichen Überlegungen vorhersagt und beide Aspekte in unsere Entscheidung einbeziehen.
Wir sind jetzt weit davon entfernt, einfach Daten in einen Lernalgorithmus zu werfen, hin zu der Gestaltung eines Lernproblems, einschließlich der Frage, die zu stellen ist, der Merkmale, die in den Datensatz aufgenommen werden sollen, der Vorverarbeitung der Daten und letztendlich des Lernalgorithmus. All diese Entscheidungen sind miteinander verbunden: Die Aufgaben, die du lösen kannst, hängen von der Verfügbarkeit der Daten ab, aber du kannst auch beschließen, bestimmte Daten zu sammeln; verschiedene Arten von Fragen erfordern verschiedene Klassen von Algorithmen; jeder Lernalgorithmus benötigt spezifische Arten der Vorverarbeitung. Offensichtlich hängen die Frage und die Datensammlung von menschlichem Wissen ab, aber selbst die Wahl der Vorverarbeitung und des Lernalgorithmus muss durch eine Kombination aus Expertenwissen und Experimenten bestimmt werden.
Machine Learning Prototyping
Wenn wir Machine Learning als Designprozess betrachten, können wir Designmethoden anwenden, um es zu lösen. Insbesondere können wir Prototyping verwenden, um verschiedene Kombinationen von Datenvorverarbeitung, Merkmalsauswahl und Lernalgorithmus zu iterieren, um einen Dialog mit Fachleuten zu ermöglichen und das gesamte Problem zu lösen.

Wie bei jedem anderen Prototyp sollte ein maschinelles Lernprototyp schnell sein, die Eigenschaften eines Endprodukts widerspiegeln und greifbar und erkundbar sein. Unsere Artificial Intelligence Insight Tools visualisieren die Daten und die Ergebnisse des maschinellen Lernens, um Fachleuten schnell eine Intuition darüber zu geben, was innerhalb der aktuellen Konzeption der Aufgabe möglich ist. Unsere Experten für Machine Learning können schnell verschiedene Kombinationen von Vorverarbeitung und Lernalgorithmen durchlaufen und so eine Vorschau auf eine vollständig entwickelte Lernlösung bieten. Gemeinsam überdenken Fachleute und Experten für Machine Learning die Aufgabe, setzen sie in den Geschäftskontext und entwickeln eine Gesamtlösung. Ob diese Lösung aus einer einzigen maschinellen Lernaufgabe, einer Kombination von maschinellen Lernaufgaben oder einem völlig anderen Ansatz besteht, unser Kunde hat den Aufwand gespart, eine große Anzahl von Daten zu sammeln, ohne überhaupt zu wissen, ob dies die richtigen Daten sind oder ob sie die richtige Frage adressieren.
Die Ergebnisse unserer prototypischen maschinellen Lernläufe können direkt in einen gesamten agilen Entwicklungsprozess integriert werden. Dies ist der Weg, Machine Learning von einer isolierten esoterischen Technik in den Mainstream der Softwareentwicklung zu führen.
Sie möchten die Potenziale Ihres Unternehmens mit modernem Machine Learning voll ausschöpfen?